Have you ever heard of the /proc filesystem before? I’m pretty sure you have if you are a regular Linux user. Here is a quick refresher.
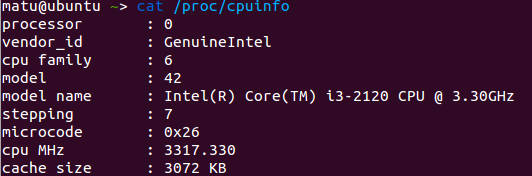
/proc is a virtual filesystem that the Linux kernel uses to expose information and allows the user to change some settings at run time. One of the most common uses is to get information about our CPU, we can use ‘cat /proc/cpuinfo’ to see it.
Navigating the proc filesystem
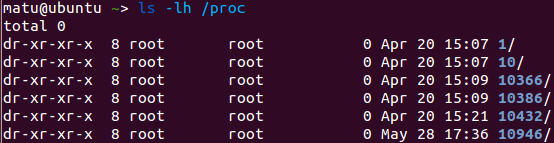
But much more interesting is the fact that all process data is stored in /proc. Each process is stored in the form of a directory with the PID of the process as its name.
Inside we will find all the information we could ever want about one process: its name, working directory, open files, status, and so on. Here is an example of how we can read the process name, using /proc/[pid]/cmdline
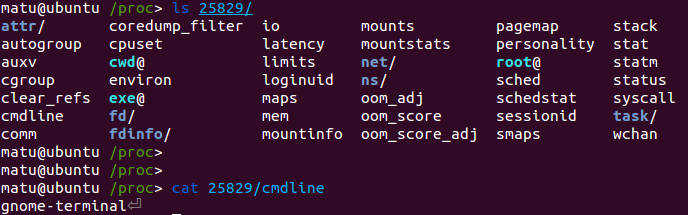
We can find the binary and the current directory under /proc/[pid]/exe and /proc/[pid]/cwd. If we do an ls -lh we will notice that these are sym links to the actual files.

Your own custom ps
Using this information we can build our own simplified version of ps using a bash script that loops over all the dirs in /proc and does a cat on cmdline. We can use basename and awk to clean up the results a bit.
|
1 2 3 4 5 |
for i in $(ls -d /proc/[0-9]* | sort -V); do echo -ne "PID $(basename $i)\t" \ && cat $i/cmdline | awk -F/ '{ if(match($NF,/[a-z]+/)) \ printf $NF; }' && echo; done |
If you would like to learn more have a look at the kernel documentation here:
https://www.kernel.org/doc/Documentation/filesystems/proc.txt
I hope you have enjoyed this post, please leave a comment if you have anything interesting to say!
